Normalization Explained with Simple Examples
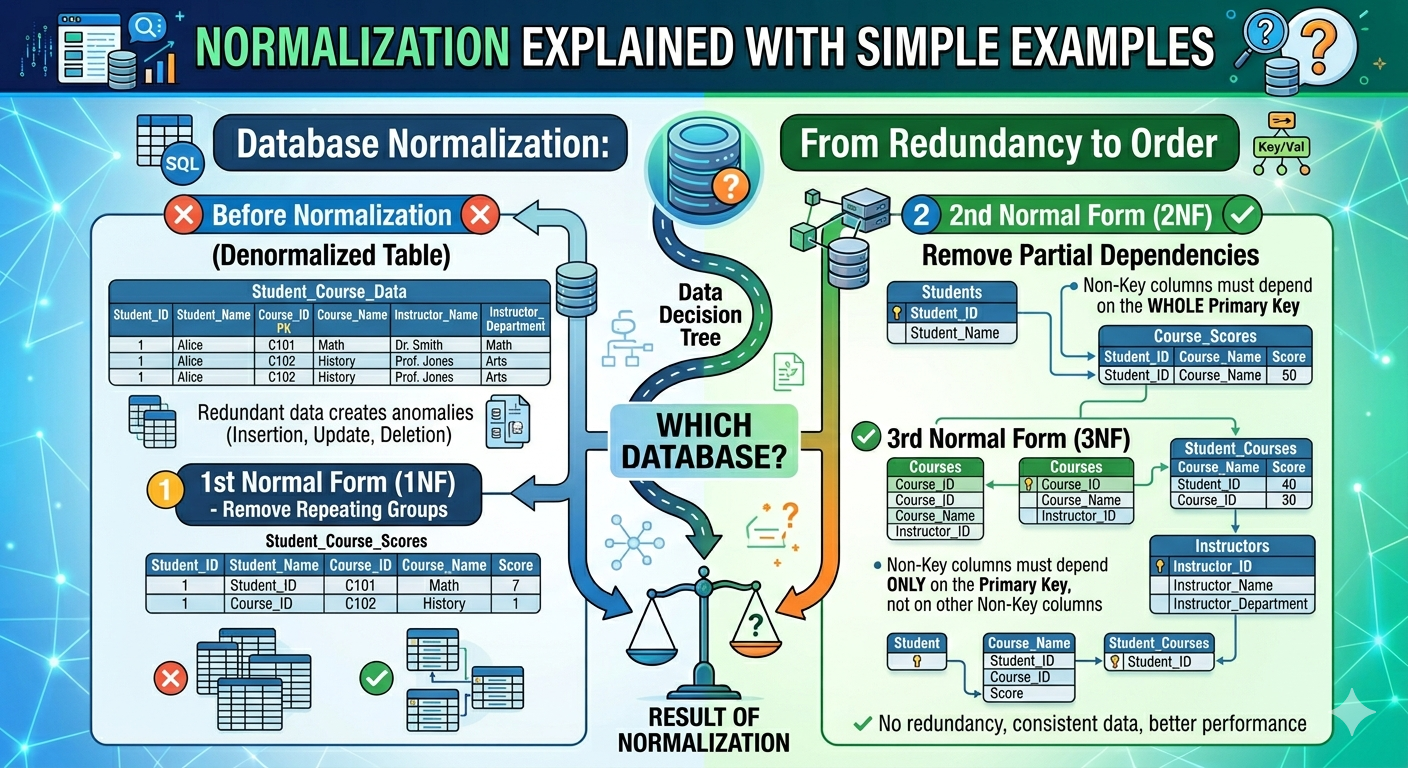
Database normalization is one of the most fundamental ideas in database design. It is the systematic organization of data in a database with the goal of reducing redundancy, eliminating inconsistencies, and improving data integrity. Normalization allows developers to structure data efficiently, ensuring that each piece of information is only kept once and that links across tables are clearly established.
Whether you're developing a small online application or a large enterprise system, understanding normalization may help you construct databases that are easier to maintain, update faster, and have fewer errors.
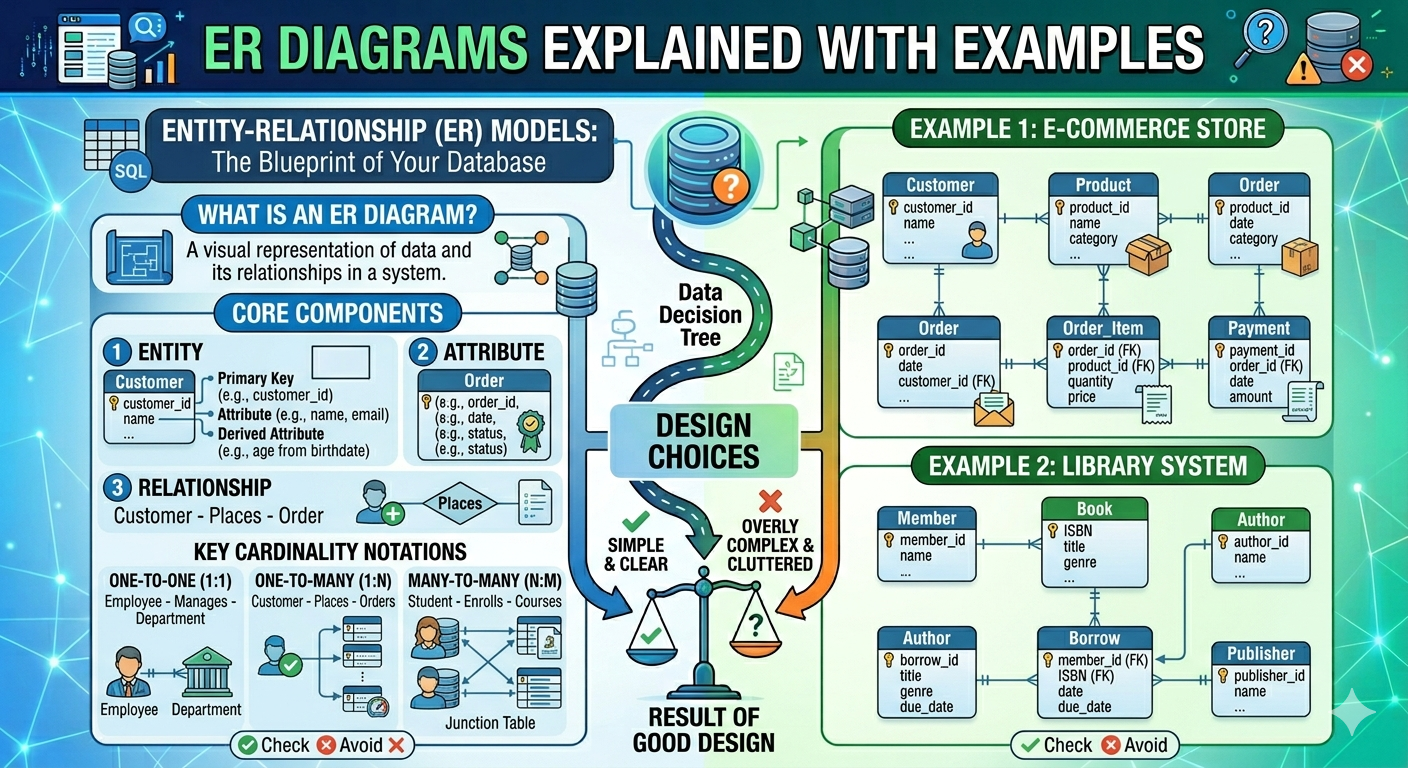
What Is Database Normalization?
A database design method called normalization avoids data duplication and gets rid of undesired traits like Insertion, Update, and Deletion Anomalies. Using relationships, normalization rules break up larger tables into smaller ones. SQL normalization serves the dual purposes of removing unnecessary (repetitive) data and ensuring logical data storage. With the introduction of the First Normal Form, the relational model's creator Edgar Codd put out the notion of data normalization, and he later expanded it with the Second and Third Normal Forms. Later, he collaborated with Raymond F. Boyce to create the Boyce-Codd Normal Form theory.
In the MySQL server, the Theory of Data Normalization is still in development. However, the third normal form is where normalization performs best in the majority of practical situations.
Normalization aims to reduce data redundancy, eliminate update anomalies, improve data integrity, and simplify maintenance. For instance, customer information is stored in a separate Customers table linked via a foreign key, rather than being repeated in every order record.
Why Is Normalization Important?
Database normalization is essential for creating databases that are efficient, accurate, and easy to manage. Normalization increases data quality and application speed by arranging it into related tables and eliminates unnecessary duplication.
Reduces Data Redundancy
Normalization ensures that the same piece of data is only saved once rather than being repeated in several records. For example, customer details are stored in a separate Customers table rather than being duplicated in every order. This saves storage space and ensures that data is consistent.
Improves Data Consistency
When data is stored in a central location, updates only need to be performed once. If a customer's phone number changes, it is updated in the Customers table and reflected anywhere that customer is referenced. This reduces the possibility of having conflicting or out-of-date information.
Prevents Data Anomalies
Normalization helps to avoid three common types of database problems:
Insertion anomalies are difficulties in inserting new data without irrelevant information.
Update anomalies occur when the same information needs to be updated in various places.
Deletion anomalies refer to the accidental loss of important data when deleting records.
These difficulties are minimized by separating related information into various tables.
Saves Storage Space
Because duplicate records are deleted, the database requires less storage space. This is especially critical in large systems with millions of records, as redundant data may significantly increase storage costs.
Makes Databases Easier to Maintain
A normalized database has an organized and logical structure. Tables are arranged based on specific entities and relationships, making the system easier to understand, edit, and extend. This facilitates troubleshooting, future development, and long-term maintenance.
First Normal Form (1NF)
The first Normal Form (1NF) is the initial step in database normalization. A table is considered to be in First Normal Form if each column includes only one value, there are no repeating groups, and each row is unique.
In simple terms, each cell in the table should contain only one piece of information. Multiple values separated by commas should not be stored in the same column because it complicates data searching, updating, and analysis.
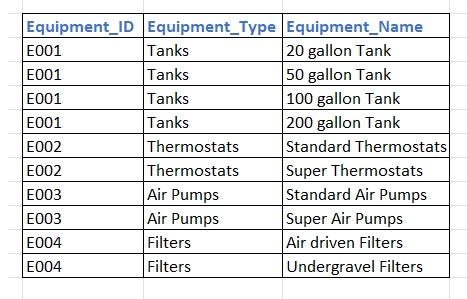
Before Applying 1NF table should show this way.

In here, the Equipment_name column contains multiple values. This violates First Normal Form because one column is storing multiple pieces of data instead of a single atomic value.
Storing multiple values in one column complicates searching for specific items, such as "50 gallon tank," as they are embedded within a list. This also makes updating equipment names more challenging, as editing a text string is required to add or remove an item. Consequently, maintaining data consistency becomes more difficult.
After Applying 1NF
After normalization, each row contains only one equipment value. Instead of storing multiple equipment in a single field, we create separate rows for each equipment.
Second Normal Form (2NF)
The Second Normal Form (2NF) is the next step after the First Normal Form. A table is in 2NF when it satisfies two conditions:
The table is now in First Normal Form (1NF).
Every non-key attribute relies on the entire primary key, not just a part of it.
This criterion is especially significant when a table has a composite primary key, which is made up of more than one column.
Consider that table (first normal form table)
here now have a composite primary key (a combination of Equipment_ID and Equipment_Name) where a Partial Dependency exists because Equipment_Type depends only on the Equipment_ID, not the specific name of the item.
Partial dependency in databases causes several issues: it results in redundant data entry, as categories like "Tanks" are stored multiple times for different sizes. This redundancy leads to update anomalies, where changing a category name requires multiple updates, risking data inconsistency.
Additionally, it wastes storage space by duplicating text strings unnecessarily. Finally, it creates insertion issues, making it difficult to add new equipment types without an accompanying specific equipment name, resulting in potential null values.
After Appling 2NF
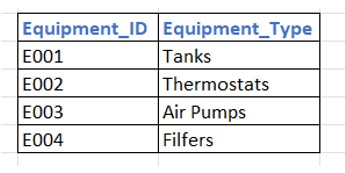
Here now the primary key is Equipment_ID. Since the key consists of only one column, partial dependency is technically impossible. And also, the non-key attribute, Equipment_Type, depends entirely on the Equipment_ID. And the category name "Tanks" is now stored only once, solving the update and storage issues found in the previous 1NF version.
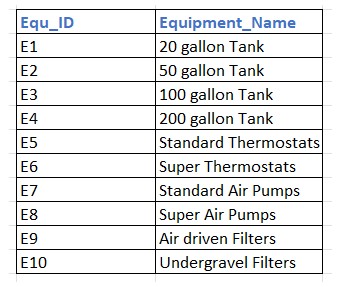
Here now each specific item now has its own unique ID (Equ_ID) from E1 to E10. Every Equipment_Name (like "20 gallon Tank" or "Super Air Pumps") is fully dependent on its specific Equ_ID. By removing the Equipment_Type column from this table, you have ensured that changes to a "Type" name do not require editing dozens of individual equipment rows.
Third Normal Form (3NF)
The Third Normal Form is the third stage of database normalization. A table is in 3NF when it satisfies these two conditions:
The table is already in First Normal Form (1NF) and Second Normal Form (2NF).
Non-key attributes depend only on the primary key, not on other non-key attributes.
In simple terms, each column in the table should explain the primary key directly, rather than another non-key column.
Consider this table
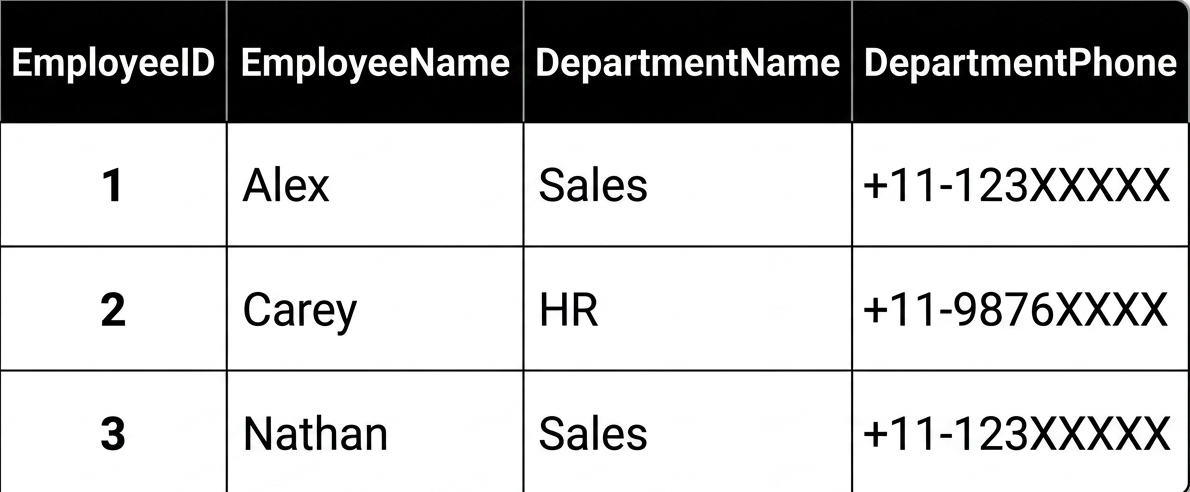
A transitive dependency occurs when one non-key column relies on another non-key column rather than directly on the primary key. For example, EmployeeID is indirectly linked to DepartmentPhone through DepartmentName, illustrating a transitive dependency.
The DepartmentPhone is repeated for every employee in the same department. This causes several issues: Data redundancy occurs when a phone number is stored multiple times. Update anomalies require changes to be made to every related row if a Sales phone number changes. Insertion anomalies prevent storing a new department phone without an existing employee. Deletion anomalies lead to loss of department information if the last employee is deleted.
After Appling 3NF
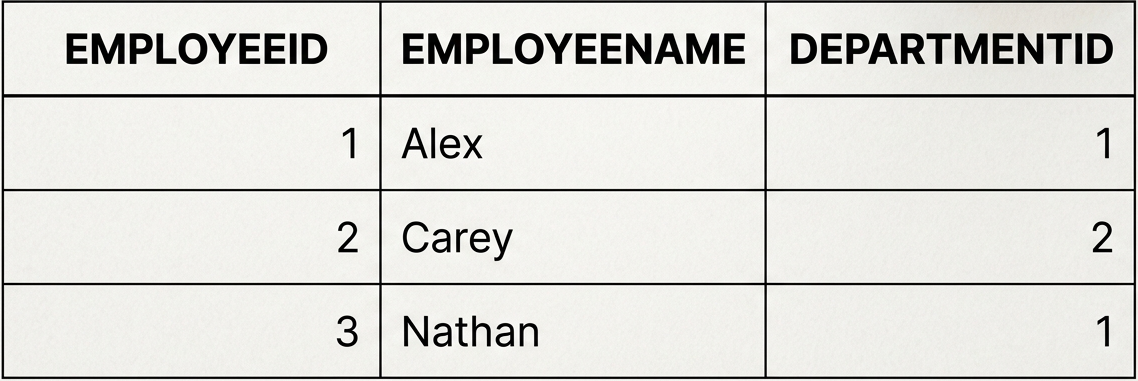
Here, the EMPLOYEENAME and DEPARTMENTID directly depend on the primary key, EMPLOYEEID, thereby eliminating any transitive dependencies. By removing department names or phone numbers previously linked to the DEPARTMENTID, the transitive link is eliminated, ensuring all information pertains directly to the employee.
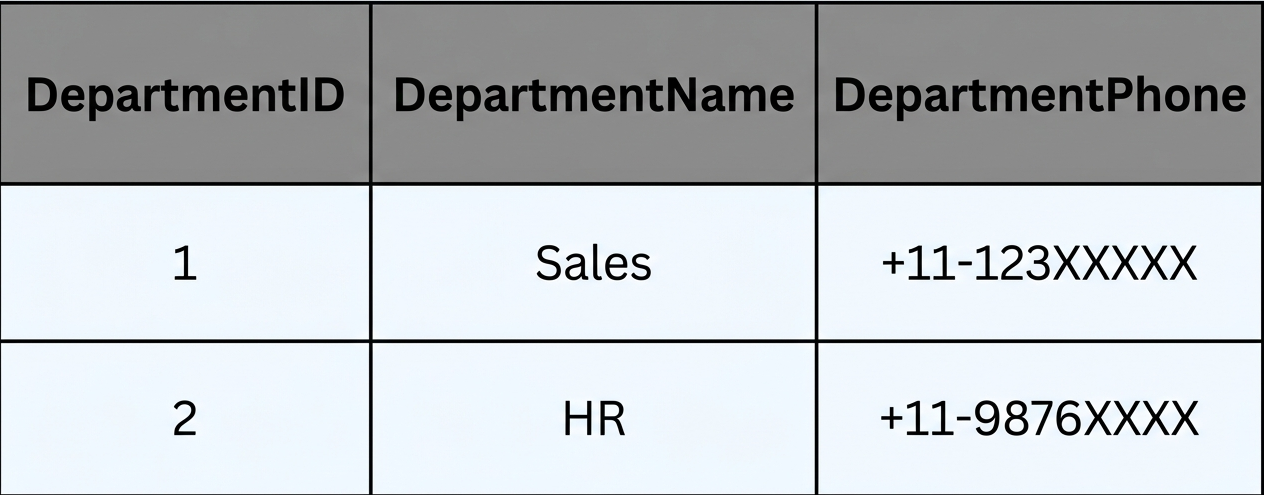
Here, the DepartmentName and DepartmentPhone depend strictly on DepartmentID. This structure allows department information to stand independently, making updates straightforward; for instance, modifying the DepartmentPhone for "Sales" affects only that entry, not all employee records. Furthermore, the table's non-key columns exclusively describe the department, preventing hidden dependencies among those fields.
Normalization is a fundamental database design approach that organizes data into well-structured tables in order to eliminate redundancy and increase integrity. Understanding the First, Second, and Third Normal Forms enables developers to create databases that are consistent, efficient, and easier to maintain. Whether you're creating a student system, an e-commerce platform, or a corporate application, normalization is essential for building dependable software and scalable database architecture.
Frequently Asked Questions
Trending Now
Recent Posts

Beginner's Guide to Software Development: Everything You Need to Know in 2026
May 30, 2026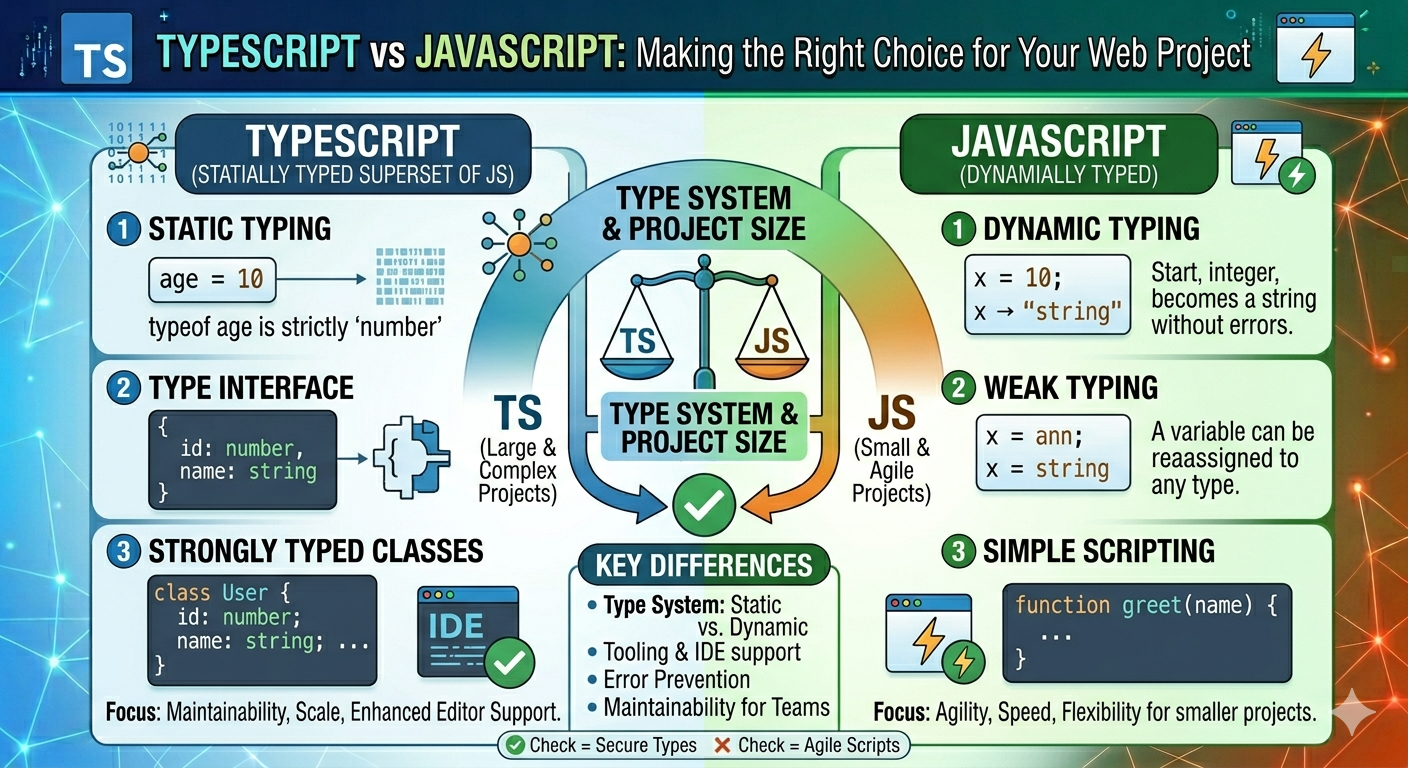
TypeScript vs JavaScript - Key Differences
May 04, 2026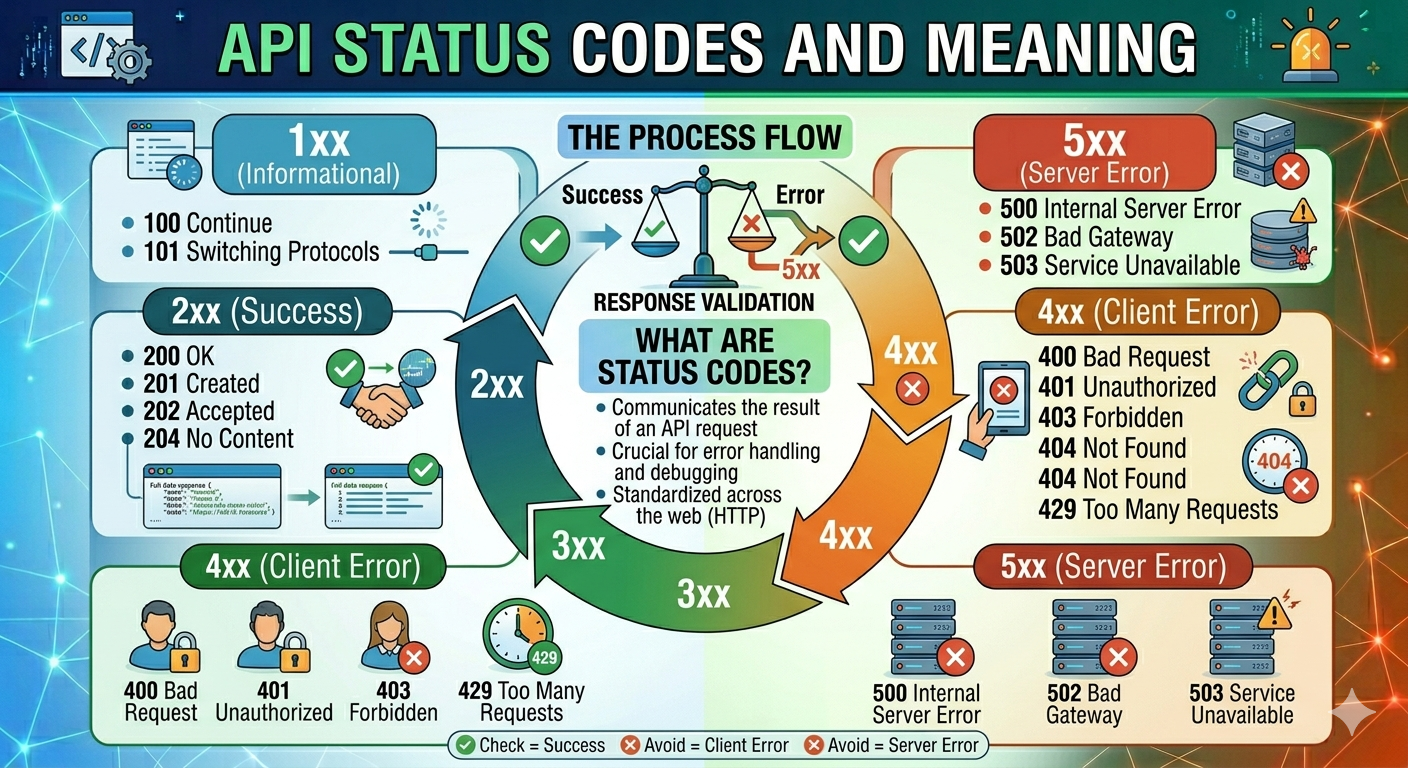
API Status Codes & Meanings
May 04, 2026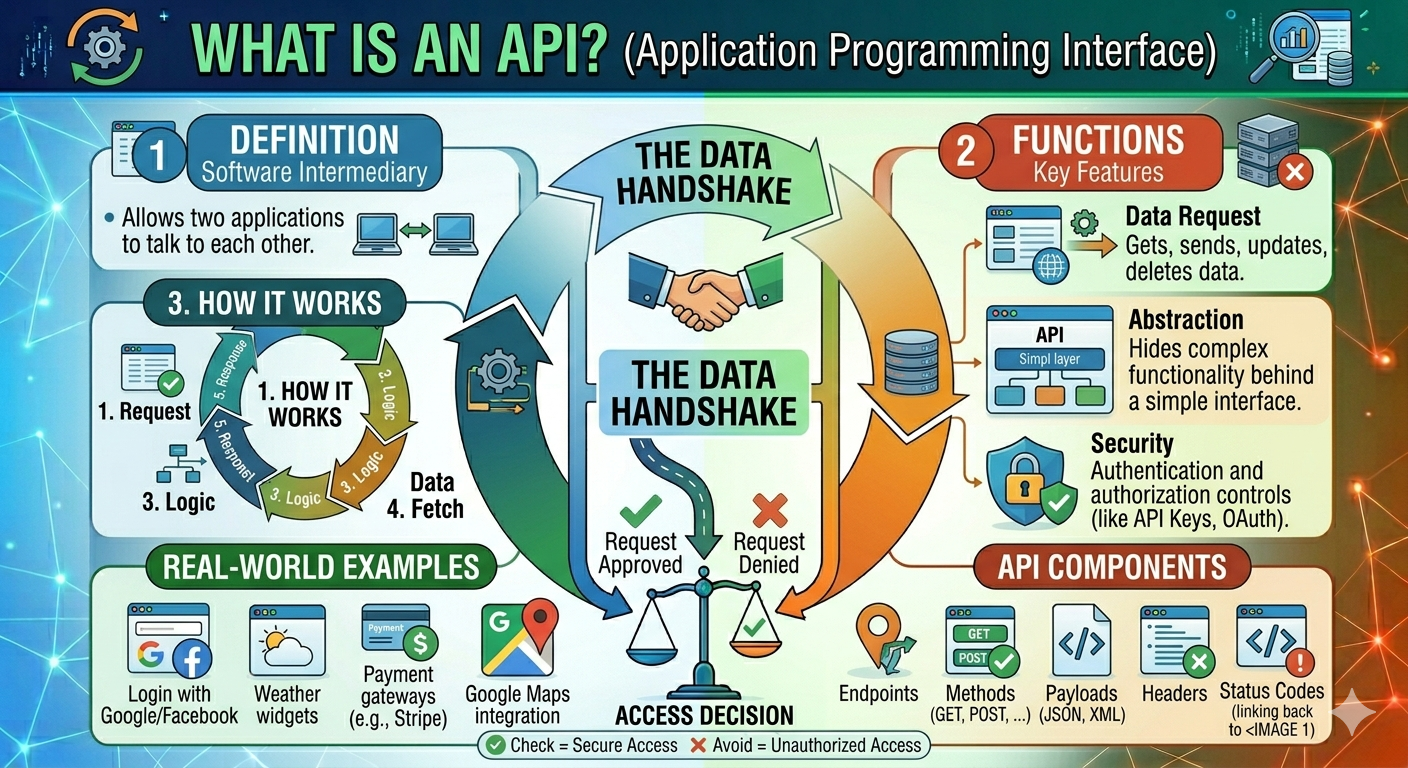
What is an Application Programming Interface (API)
May 04, 2026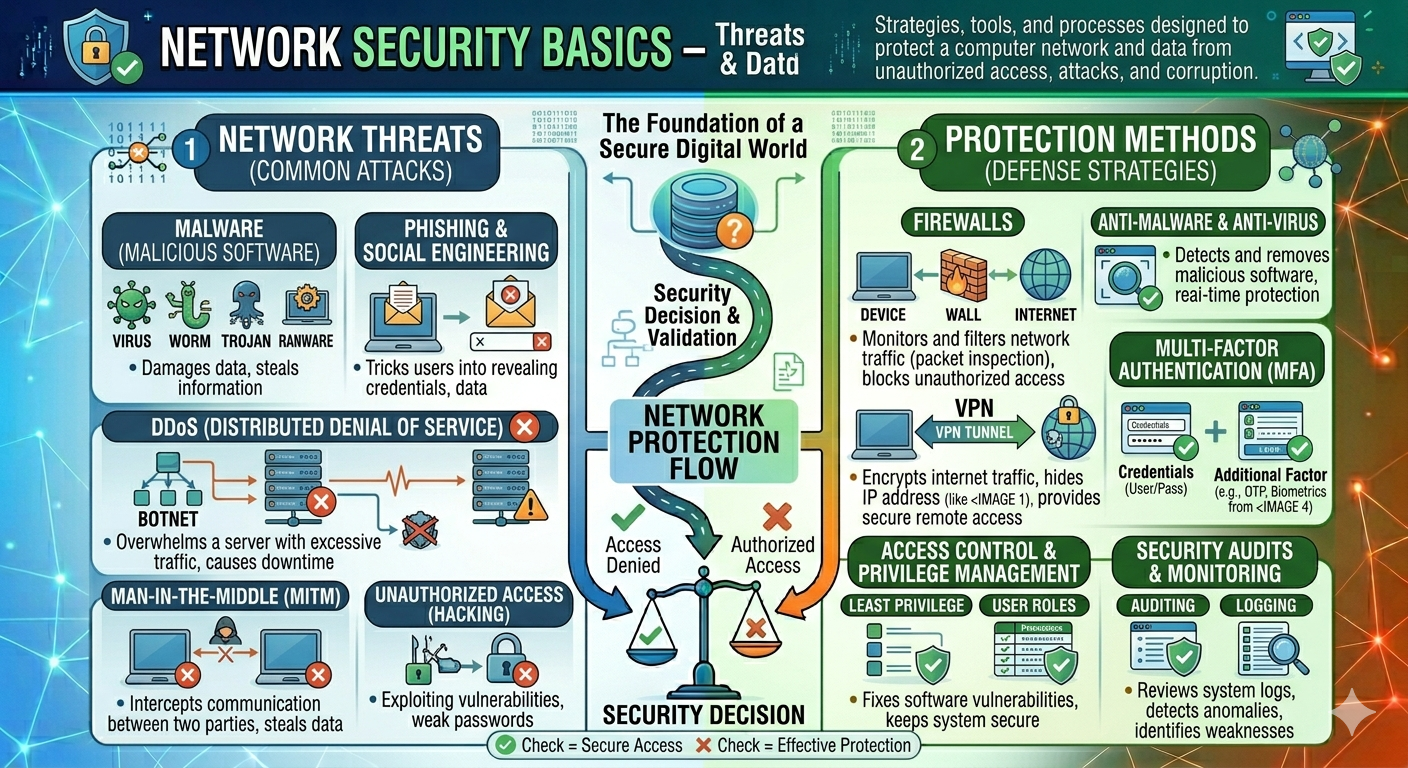
Network Security Basics – Threats & Protection Methods
May 04, 2026